
Hi !
I have a ToDo in my list, to add some new drone demos. In order to do this, I was planning to perform some tests with pretrained models and use them. The 1st 2 in my list are Yolo and MobileNetSSD (see references).
YoloV3
Let’s start with one of the most popular object detection tools, YOLOV3. The official definition:
YOLO (You Only Look Once) is a real-time object detection algorithm that is a single deep convolutional neural network that splits the input image into a set of grid cells, so unlike image classification or face detection, each grid cell in YOLO algorithm will have an associated vector in the output that tells us:
If an object exists in that grid cell.
The class of that object (i.e label).
The predicted bounding box for that object (location).
YoloV3
I pickup some sample code from GitHub repositories and, as usual, from PyImageSearch (see references), and I created a real-time object detection scenario using my webcam as the input feed for YoloV3.
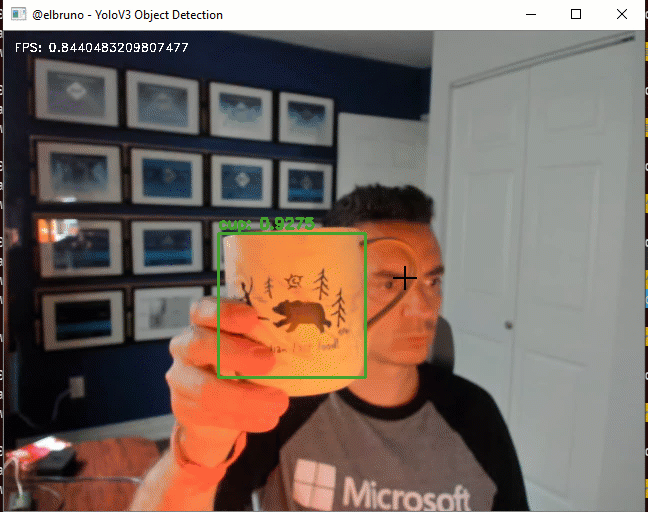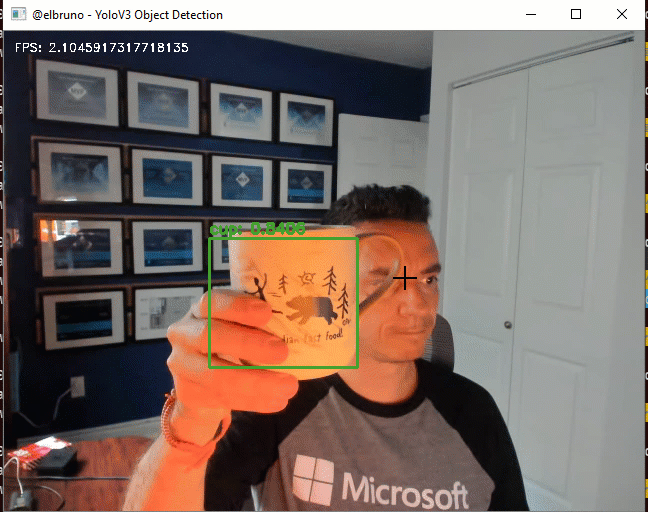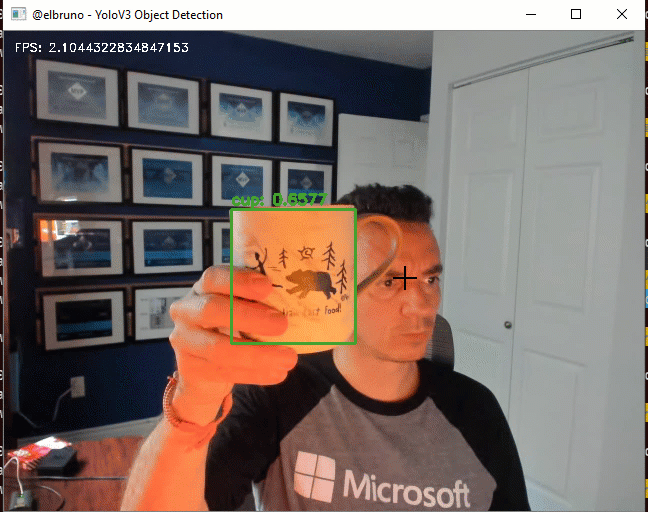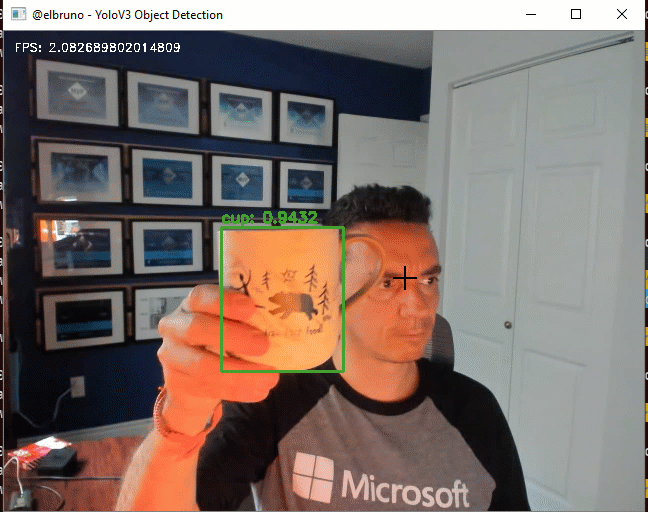
The final demo, works great; we can use the 80 classes that YoloV3 supports and it’s working at ~2FPS.
MobileNetSSD
Another very popular Object Detection Tool is MobileNetSSD. And, the important part here is SSD, Single Shot Detection. Let’s go to the definition:
Single Shot object detection or SSD takes one single shot to detect multiple objects within the image. As you can see in the above image we are detecting coffee, iPhone, notebook, laptop and glasses at the same time.
It composes of two parts
– Extract feature maps, and
– Apply convolution filter to detect objects
SSD is developed by Google researcher teams to main the balance between the two object detection methods which are YOLO and RCNN.
There are specifically two models of SSD are available
– SSD300: In this model the input size is fixed to 300×300. It is used in lower resolution images, faster processing speed and it is less accurate than SSD512
– SSD512: In this model the input size is fixed to 500×500. It is used in higher resolution images and it is more accurate than other models.
SSD is faster than R-CNN because in R-CNN we need two shots one for generating region proposals and one for detecting objects whereas in SSD It can be done in a single shot.
The MobileNet SSD method was first trained on the COCO dataset and was then fine-tuned on PASCAL VOC reaching 72.7% mAP (mean average precision).
For this demo, I’ll use the SSD300 model. Even, if the drone support better quality images and the SSD500 model works with bigger images, SSD300 is a good fit for this.
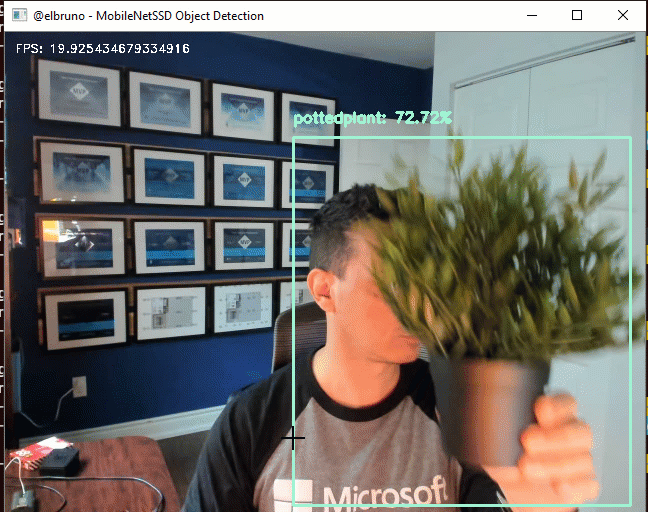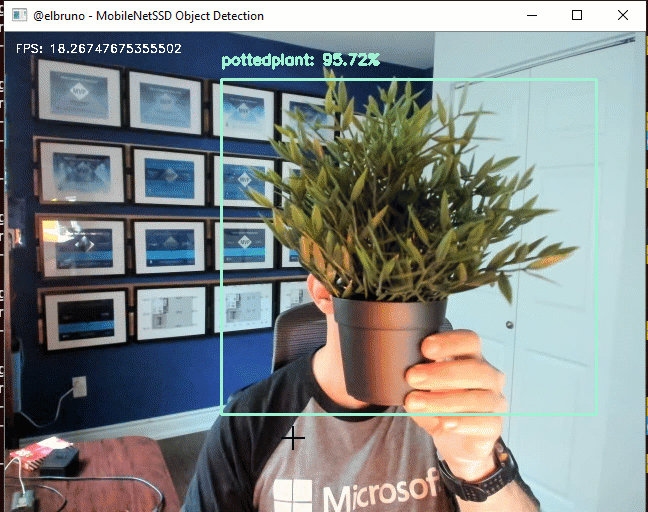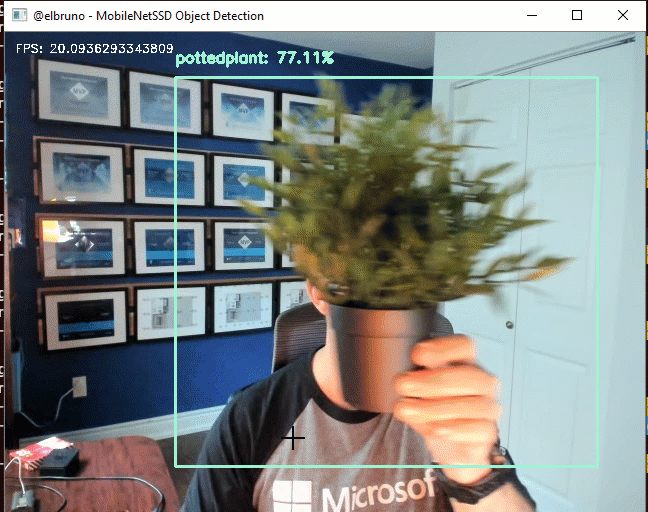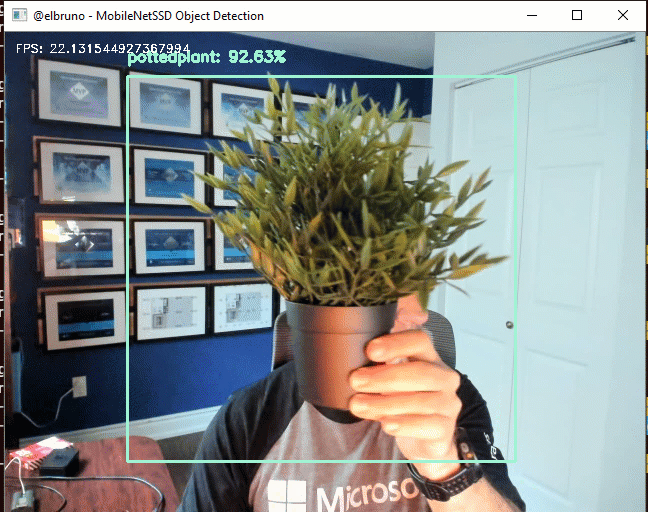
This sample works at ~20FPS, and this triggered my curiosity to learn more about the 2nd one. I started to read a lot about this, and found some amazing articles and papers. At the end, if you are interested on my personal take, I really enjoyed this 30 min video about the different detectors side-by-side
Source Code
YoloV3 webcam live object detection
MobileNetSSD webcam live object detection
Happy coding!
Greetings
El Bruno
More posts in my blog ElBruno.com.
More info in https://beacons.ai/elbruno
Resources

Leave a comment