
Coding4Fun Drone 🚁 posts
- Introduction to DJI Tello
- Analyzing Python samples code from the official SDK
- Drone Hello World ! Takeoff and land
- Tips to connect to Drone WiFi in Windows 10
- Reading data from the Drone, Get battery level
- Sample for real time data read, Get Accelerometer data
- How the drone camera video feed works, using FFMPEG to display the feed
- Open the drone camera video feed using OpenCV
- Performance and OpenCV, measuring FPS
- Detect faces using the drone camera
- Detect a banana and land!
- Flip when a face is detected!
- How to connect to Internet and to the drone at the same time
- Video with real time demo using the drone, Python and Visual Studio Code
- Using custom vision to analyze drone camera images
- Drawing frames for detected objects in real-time in the drone camera feed
- Save detected objects to local files, images and JSON results
- Save the Drone camera feed into a local video file
- Overlay images into the Drone camera feed using OpenCV
- Instance Segmentation from the Drone Camera using OpenCV, TensorFlow and PixelLib
- Create a 3×3 grid on the camera frame to detect objects and calculate positions in the grid
- Create an Azure IoT Central Device Template to work with drone information
- Create a Drone Device for Azure IoT Central
- Send drone information to Azure IoT Central
- Using GPT models to generate code to control the drone. Using ChatGPT
- Generate code to control the 🚁 drone using Azure OpenAI Services or OpenAI APIs, and Semantic Kernel
Hi !
We already have the drone camera feed ready to process, so let’s do some Image Segmentation today. As usual, let’s start with the formal definition of Image Segmentation
In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as image objects). The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.[1][2] Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
Wikipedia, Image Segmentation
The result of image segmentation is a set of segments that collectively cover the entire image, or a set of contours extracted from the image (see edge detection). Each of the pixels in a region are similar with respect to some characteristic or computed property, such as color, intensity, or texture. Adjacent regions are significantly different with respect to the same characteristic(s).[1] When applied to a stack of images, typical in medical imaging, the resulting contours after image segmentation can be used to create 3D reconstructions with the help of interpolation algorithms like marching cubes.[3]
The technique is amazing, and once is attached to the drone camera, we can get something like this:
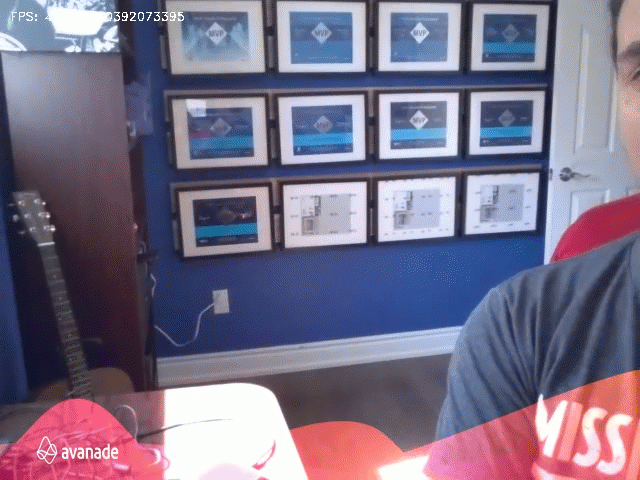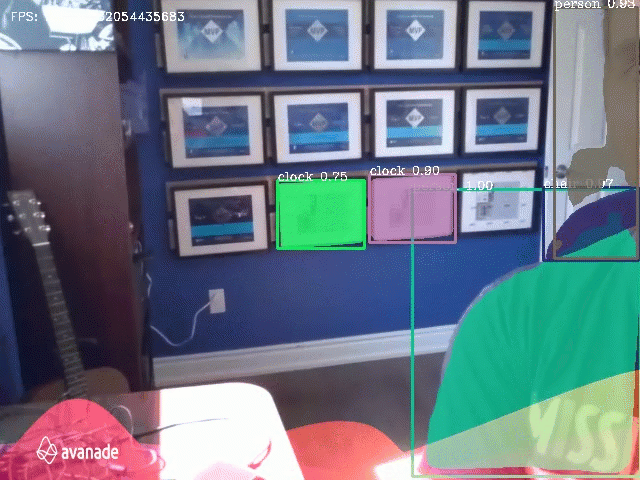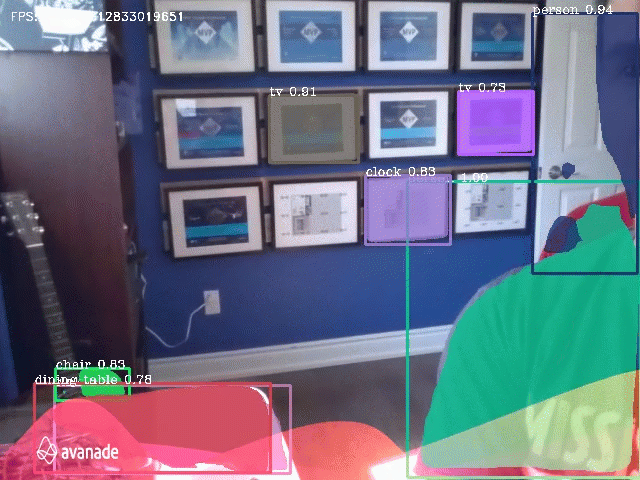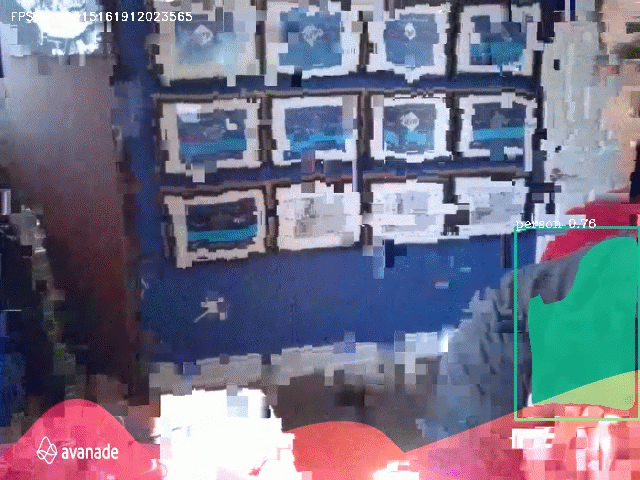
I used a Python library to make most of the work: PixelLib. It was created by an amazing set of colleagues, so please check the references and take a look at the project description.
PixelLib: is a library built for an easy implementation of Image Segmentation in real life problems. PixelLib is a flexible library that can be integrated into software solutions that require the application of Image Segmentation.
PixelLib
Once I have all the pieces together, I pulled a Pull Request with a single change to allow the use of OpenCV and webcam camera frames and I got a basic demo up and running.
Let’s review the code
- Line 147. That’s it, a single line which performs the instance segmentation, and also display the bounding boxes.
Sample Code
I’ll show a couple of live demos of this in my next Global AI Community, Drone AI demos. Check my next event sections!
Happy coding!
Greetings
El Bruno
More posts in my blog ElBruno.com.
More info in https://beacons.ai/elbruno
References
- Wikipedia, Image Segmentation
- Image Segmentation With 5 Lines 0f Code
- GitHub, PixelLib

Leave a comment